Исходное сырье, поставщики, дробление сырья, тонкий помол компонентов, температура обжига сырьевой смеси, расход электроэнергии оказывают существенное влияние на качество и стоимость продукта. Параметрами портландцемента являются гранулометрический состав, размер, удельная поверхность частиц (см2/г), густота, равномерность изменения объема, химический и минералогический состав. Качество продукта оценивается по следующим ключевым показателям: предел прочности на сжатие и изгиб, равномерность изменения в процессе гидратации и др. Тонкость помола характеризуется величиной остатка порошка и величиной прохода порошка сквозь сито, удельной поверхностью зерен, гранулометрическим составом.
Измеряемые показатели: начало схватывания, конец схватывания, тонкость помола, коррозийная стойкость, огнеупорность, гидрофорбность и др. Предел прочности при сжатии определяется стандартом в возрасте 2 и 28 суток. С помощью классических статистических методов и технологий дейта майнинга, включая CART модели (деревья классификации и регрессии), строятся предсказательные модели зависимости скорости схватывания, пределов прочности на сжатие и изгиб от компонент портландцемента. Построенные модели позволяют оптимизировать технологический процесс, повысить качество продукции.
Данный кейс подробно разбирается на курсе Академии Анализа Данных "Мониторинг и анализ производственных процессов: методология, технология, кейсы"
Постановка задачи
Рассматривается важная практическая задача – установление зависимости между компонентами портландцемента и выделяющимся теплом при его отвердевании. Имеются табличные результаты экспериментального исследования тепла, выделяющегося про отвердевании портландцемента. Данные устанавливают связь между количеством четырех компонент (3CaO·Al2O3, 3CaO·SiO2, 4CaO·Al2O3·Fe2O3, 2CaO·SiO2) в клинкерах, из которых изготовлен цемент, и выделившимся теплом.
Исходные данные
Независимые переменные (предикторы):
- X_1 – количество трикальций-алюмината 3CaO·Al2O3;
- Х_2 – количество трикальций-силиката 3CaO·SiO2;
- Х_3 – количество тетракальций-алюминиум-феррита 4CaO·Al2O3·Fe2O3;
- Х_4 – количество дикальций-силиката 2CaO·SiO2
Зависимая переменная: Y = X_5 – выделившееся тепло в калориях на грамм цемента;
X_1, X_2, X_3 и X_4 измеряются в процентах от веса клинкера, из которого производится цемент.
Исходные данные
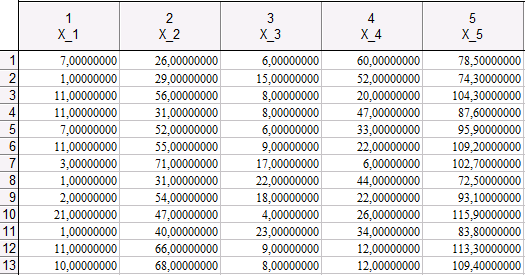
Из первой строки таблицы, например, видно, что при значениях Х_1 = 7, Х_2 = 26, Х_3 = 6, Х_4 = 60 выделяется 78,5 калорий тепла.
Из третьей строки видно, что при значениях Х_1 = 11, Х_2 = 56, Х_3 = 8, Х_4 = 20 выделяется 104,3 калории тепла.
Для повышения качества цемента важно найти зависимость между компонентами цемента и выделяющимся теплом. Предсказательные модели можно построить в ряде модулей STATISTICA, мы начнем работать в модуле множественная регрессия.
Модуль «Множественная регрессия»
В меню «Анализ» выбираем модуль «Множественная регрессия» и запускаем его.
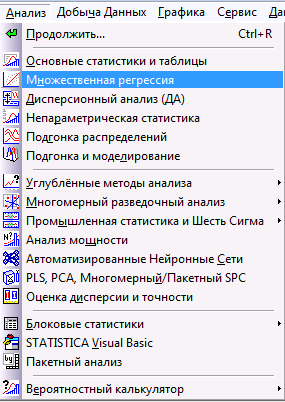
В открывшемся диалоговом окне нажимаем на кнопку «Переменные»: в качестве зависимой переменной выбираем X_5, в качестве независимых – X_1, X_2, X_3 и X_4. Во вкладке «Дополнительно» ставим галочку напротив «Пошаговая или гребневая регрессия». С помощью этой опции можно автоматизировать процесс выбора наиболее информативной в смысле R2 (доля объясненной дисперсии) модели регрессии.
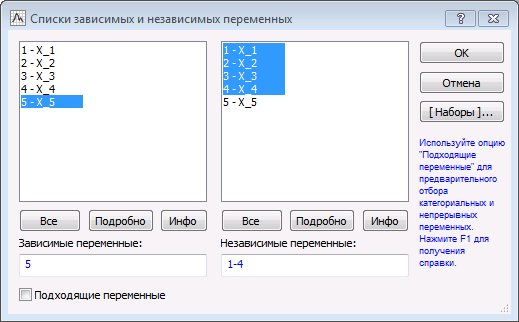
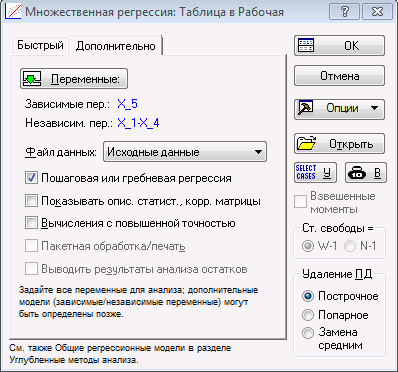
Далее откроется диалоговое окно «Определение модели». В строке «Процедура» выбираем «Пошаговая с включением».
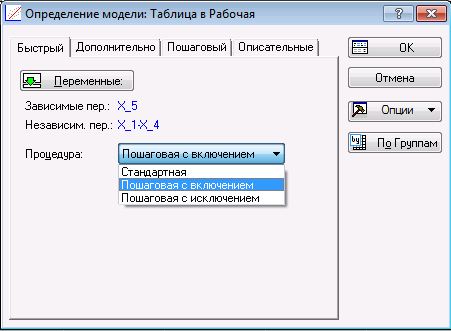
Нажимаем «ОК», программа проведет вычисления и выдаст окно результатов, поеказанное ниже.
Результаты регрессии
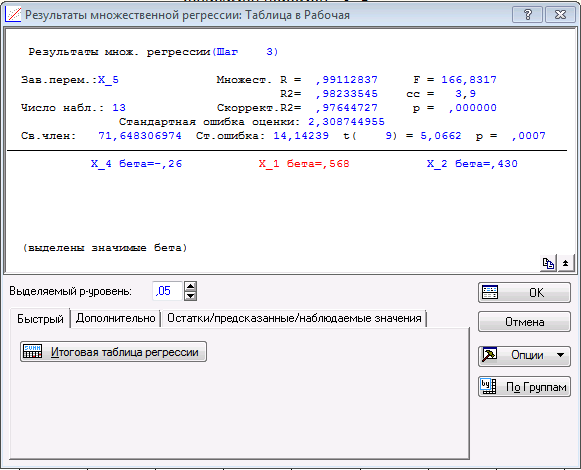
Просмотрим это окно, двигаясь сверху вниз. В верхней части окна приведены:
- название зависимой переменной, число наблюдений;
- коэффициент множественной корреляции, коэффициент детерминации R2, скорректированный R2;
- значение F-статистики для проверки гипотезы H0: линейная связь между зависимой и независимыми переменными отсутствует,
- степени свободы распределения Фишера сс, уровень значимости р, соответствуюший F-статистике;
- стандартная ошибка оценки, значение свободного члена, значение t-статистики для проверки гипотезы о равенсте свободного члена нулю, соответствующий уровень значимости p.
Итоговая таблица
Нажимаем кнопку «Итоговая таблица регрессии» для просмотра таблиц:
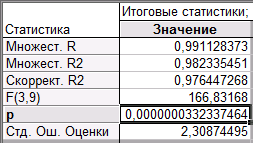
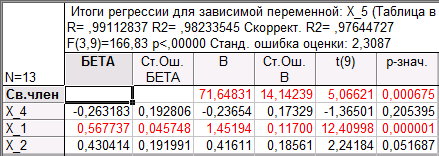
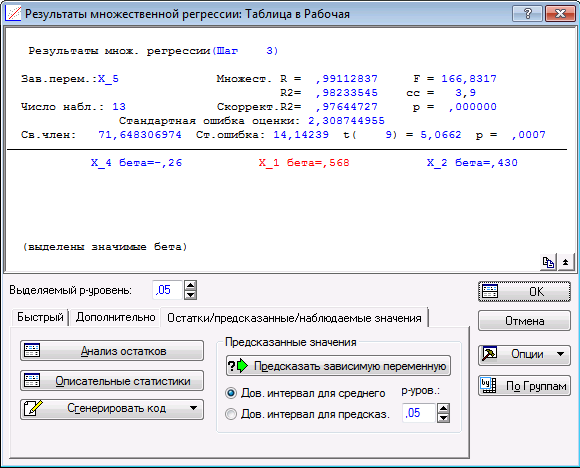
Из таблицы «Итоговые статистики» следует, что значение коэффициента детерминации R2 близко к 1, а p-значение меньше 0,05, значит модель регрессии (коэффициенты взяты из столбца «В» таблицы «Итоги регрессии для зависимой переменной»)
X_5 = 71,64831 + 1,45195·X_1 + 0,41611·X_2 – 0,23654·X_4
признается значимой, и очень хорошо объясняет дисперсию переменной X_5.
В столбце «t(9)» стоят значения статистики Стьюдента для проверки гипотезы о равенстве нулю соответствующего коэффициента, а в столбце «р-знач.» - соответствующие уровни значимости отклонения этой гипотезы. Достаточно малым этот уровень является только для коэффициента при X_1. В то же время данная модель наиболее информативная в смысле R2, значит она информативней, чем модель с одним регрессором X_1. Это говорит о том, что следуют продолжить изучение линейной связи между X_5 и (X_1, X_2, X_3, X_4), анализируя как их содержательный смысл, так и матрицу парных корреляций.
Анализ нормальности остатков
Дополним результаты регрессии анализом нормальности остатков. Для этого перейдем во вкладку «Остатки/предсказанные/наблюдаемые значения» диалогового окна «Результаты множественной регрессии». Далее нажимаем кнопку «Анализ остатков», а в появившемся окне на вкладке «Диаграммы рассеяния» нажимаем кнопку «Предсказанные и остатки». Также следует построить «Гистограмму остатков», которая находится во вкладке «Остатки» диалогового окна «Анализ остатков», и «Нормальный график остатков», который находится во вкладке «Вероятностные графики». Имеется всего 13 наблюдений, гистограмма остатков и нормальный график остатков никакой существенной информации не дадут.
График «Предсказанные значения и остатки» говорит о несмещенности оценки остатков:
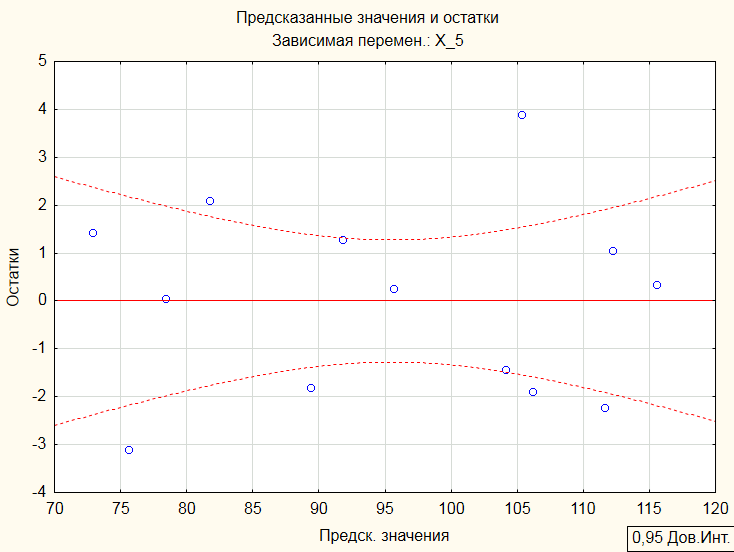
Парные корреляции
Перейдем во вкладку «Остатки/предсказанные/наблюдаемые значения». Далее нажимаем кнопку «Описательные статистики», а в появившемся окне на вкладке «Быстрый» или «Дополнительно» нажимаем кнопку «Корреляции».

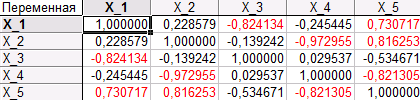
Из матрицы видно, что переменные X_2 (трикальций-силикат 3CaO·SiO2) и X_4 (дикальций-силикат 2CaO·SiO2) сильно коррелированны. Имеет место дублирование информации, и потому, по-видимому, есть возможность перехода от исходного числа признаков (переменных) к меньшему числу, иными словами, сократить размерность задачи.
Сравнение моделей с регрессорами (X_1, X_2) и (X_1, X_4)
Рассмотрим две регрессионные модели: 1) с регрессорами X_1, X_2; 2) с регрессорами X_1, X_4. Опять воспользуемся модулем «Множественная регрессия». В качестве зависимой переменной выбираем X_5, а в качестве независимых в первом случае X_1 и X_2, а во втором случае X_1 и X_4.
Проделаем уже описанные шаги для этих моделей и получим следующие результаты:
1). регрессоры X_1, X_2:
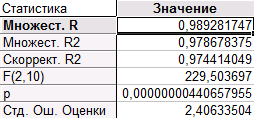
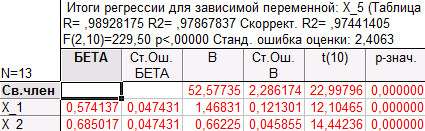
Уравнение регрессии: X_5 = 52,57735 + 1,46831·X_1 + 0,66225·X_2
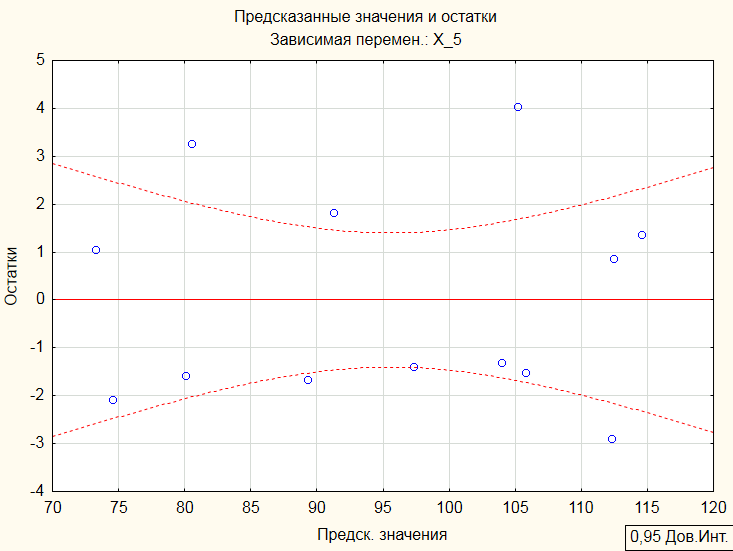
График «Предсказанные значения и остатки»:
2). регрессоры X_1, X_4:
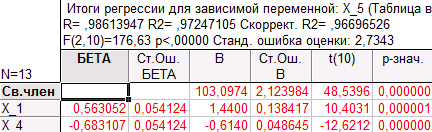
Уравнение регрессии: X_5 = 103,0974 + 1,4400·X_1 - 0,6140·X_4
График «Предсказанные значения и остатки»:
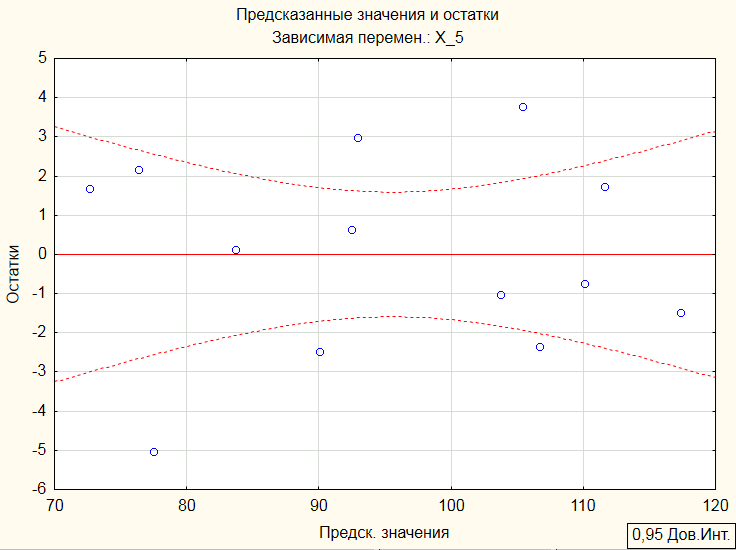
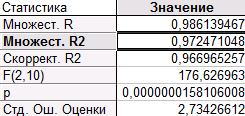
Как мы видим, в обеих моделях коэффициент детерминации R2(0,978678375 и 0,972471048) близок к коэффициенту детерминации (0,982335451) в модели с тремя регрессорами (X_1, X_2, X_4), но в этих моделях оба коэффициента при регрессорах значимы. Распределение точек на графиках «Предсказанные значения и остатки» говорит о несмещенности оценкок ошибок. Поэтому следует отдать предпочтение модели с двумя регрессорами, а именно с X_1 и X_2, так как R2 в этом случае больше, чем в модели с регрессорами X_1, X_4.
Таблица предсказанных значений
Приведем таблицу предсказанных значений и остатков для выбранной модели с регрессорами X_1, X_2. Для этого перейдем во вкладку «Остатки/предсказанные/наблюдаемые значения» диалогового окна «Результаты множественной регрессии». Далее нажимаем кнопку «Анализ остатков», а в появившемся окне на вкладке «Быстрый» или «Дополнительно» нажимаем кнопку «Остатки и предсказанные». Получаем следующую таблицу:
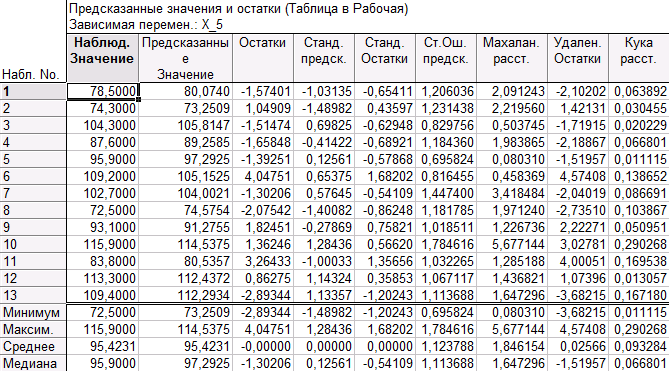
Выводы
На основе проведенного регрессионного анализа была построена предсказательная модель: X_5 = 52,57735 + 1,46831·X_1 + 0,66225·X_2. В отличие от моделей с большим числом регрессоров, в данной модели все коэффициенты являются значимыми на уровне α = 0,05. Также данная модель является наилучшей в смысле R2 среди моделей с не более чем двумя регрессорами. Однако, анализ показал, что есть модели с очень близкими значениями коэффициентов детерминации и объясненной дисперсии, поэтому окончательный выбор модели следует делать исходя из дополнительной информации, наример физической природе переменных и их характерных особенностях. С помощью методов дейта майнинга и машинного обучения можно построить выскоточные модели определения характеристик материалов от состава и параметра технологических процессов.
Более подробно методы предиктивной аналитики в приложении к изготовлению современных материалов излагаются в курсе Академии "Мониторинг и анализ производственных процессов: методология, технология, кейсы"
Литература
- Боровиков В. П., Ивченко Г. И. Прогнозирование в системе STATISTICA в среде Windows. Основы теории и интенсивная практика на компьютере. – М.: Финансы и статистика, 1999.
- Боровиков В. П. STATISTICA. Искусство анализа данных на компьютере: для профессионалов. 3-е изд. – СПб.: Питер, 2003
- Хальд А. Математическая статистика с техническими приложениями




